
When Knowledge Graphs Mislead
Seven knowledge graph quality problems that undermine GraphRAG performance and how to detect them


In my previous post, I talked about Retrieval-Augmented Generation (RAG) as a way to enhance large language models by grounding their outputs in external knowledge retrieved at inference time. Now, if you’ve been following the news and trends around such systems, there’s a good chance you’ve also come across the idea of GraphRAG, a variation of RAG that replaces unstructured text retrieval with structured knowledge retrieval from a knowledge graph, promising better performance. But is that always the case?
In this post, I am taking a closer look at GraphRAG systems and I am walking through seven common knowledge graph quality problems that can undermine their performance.
How GraphRAG works
A knowledge graph is a structured representation of facts, where entities are linked through well-defined relationships (see image below). Unlike text, which is often ambiguous and noisy, a knowledge graph, when designed carefully, encodes meaning explicitly, succinctly, and in a way that supports precise querying and logical inference. This makes it particularly appealing in the context of RAG applications, where the quality of retrieval depends not just on surface-level similarity but on the structure and semantics of the data itself.
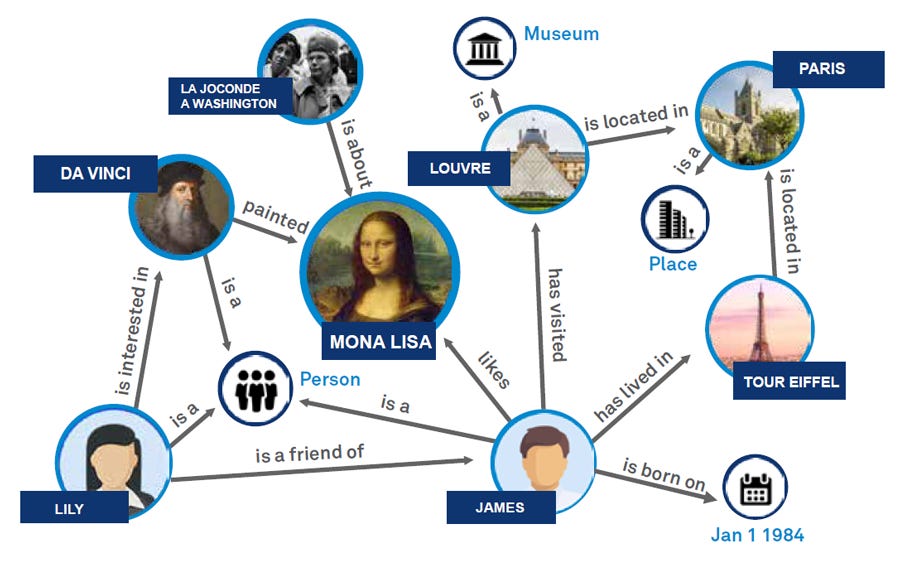
The idea of GraphRAG is simple: instead of retrieving large, semantically similar text chunks from free-form text to feed into the language model, the system queries a knowledge graph to retrieve specific entities and relationships directly relevant to the question. This, in theory, allows for more precise, deduplicated, and multi-hop retrieval, where facts can be aggregated from multiple sources and traversed across connected nodes.
However, the reality is often less ideal.
The Role of Knowledge Graph Quality
Many of the knowledge graphs used in GraphRAG pipelines lack the semantic accuracy, consistency, or even content needed to support reliable retrieval and grounding. That’s often because they are auto-generated from unstructured data (using LLMs or other ML-based methods) or assembled ad hoc from disparate sources without a coherent schema or modeling strategy. As a result, retrieval becomes superficial, and answers may appear grounded, but are in fact misleading or incomplete.
But what can be wrong with a knowledge graph? Well, here are seven common problems.
Problem 1: False Knowledge
In this case, the graph contains assertions that are factually incorrect, either due to extraction errors, faulty source data, or careless modeling. These kinds of errors are quite common in automatically constructed knowledge graphs, especially those built at scale from unstructured sources.
Some humorous but real examples come from DBpedia, a well-known knowledge graph automatically extracted from Wikipedia. As of this writing, DBpedia lists Machine Learning as a Music Genre, Politics as a Company, and Biology as a University.
Obviously, when such statements are used as context in a GraphRAG pipeline they introduce false grounding. The model may confidently generate answers that are justified by the context, but completely wrong in reality. And because the error stems from a knowledge source assumed to be authoritative, these hallucinations can be easy to trust.
Problem 2: Vague and Subjective Knowledge
In this case, the knowledge graph contains assertions that are based on vague, subjective, or context-dependent predicates. A good example of this comes from ESCO, the European Commission’s knowledge graph of occupations and skills. ESCO defines concepts for various occupations and skills, and links each occupation to the skills deemed essential for it. However, the notion of essentiality in this context is highly subjective as, in most cases, there are no universally accepted criteria that cleanly separate essential from non-essential skills. To see this in practice, just try asking 100 AI professionals which skills are essential for their work and which not; I am pretty sure you will get highly different and contradicting answers.
In practice, the truth value of vague assertions like these varies from person to person and from context to context. When such statements are used as context in a GraphRAG system, the generated answers may sound authoritative but are unlikely to be universally acceptable or verifiable. This undermines the reliability and objectivity that knowledge-based grounding is supposed to offer.
Problem 3: Inconsistent Knowledge
In this case, the graph contains assertions that semantically contradict one another; for example, the same entity being assigned two mutually exclusive types or holding incompatible relationships. Imagine a graph where the same person is typed both as a Software Engineer and a Medical Device, or where an entity is described as both part of and not part of a certain organization.
Such inconsistencies create confusion during retrieval. Depending on how the data is indexed or traversed, the system may retrieve conflicting facts that cannot be reconciled by the language model. As a result, generated answers may hedge, contradict themselves, or hallucinate in an attempt to resolve the ambiguity, thus damaging the trustworthiness of the context and making reliable grounding difficult.
Problem 4: Missing Knowledge
In this case, key entities, relationships, or facts that should be present in the knowledge graph are simply absent. This makes it impossible for the system to retrieve the necessary context to answer certain questions, even if the retrieval and generation components are functioning correctly.
For example, a knowledge graph in a healthcare application might include information about diseases and treatments, but omit specific comorbidity relationships or drug interactions. In such cases, a query like “What treatments are recommended for patients with both condition A and condition B?” will fail to retrieve anything useful as the graph never had that knowledge to begin with.
Problem 5: Irrelevant Knowledge
In this case, the knowledge graph contains content that is not meaningful or useful for the specific task, user goal, or domain. This might include generic facts, out-of-scope entities, or relationships that clutter the graph without adding value to the system’s intended purpose.
For example, in a knowledge graph built to support financial risk assessment, including detailed metadata about product packaging or historical company slogans may seem harmless, but during retrieval, this irrelevant information competes with more important facts. As a result, the system may retrieve off-topic context that distracts the language model or dilutes the grounding signal.
Problem 6: Inconcise Knowledge
In this case, the knowledge graph is bloated with redundant or near-duplicate assertions, making it harder for the system to retrieve clean, focused, and non-repetitive context. This typically happens when the graph includes inconsistent labels, repeated facts across different nodes, or multiple representations of the same entity (e.g. IBM, International Business Machines and I.B.M. as separate nodes).
Such redundancy reduces retrieval precision by increasing the chance of surfacing duplicate or semantically overlapping information. This can confuse the language model, which may treat similar statements as separate facts or repeat them verbatim in the generated response. In some cases, it also leads to longer and less coherent answers, especially when retrieval budgets are tight.
Problem 7: Incomprehensible Knowledge
In this case, the graph includes elements whose natural language names and descriptions are abstract, ambiguous, underspecified, or simply poorly named, making them difficult for LLMs to interpret or use meaningfully. This is especially common in graphs generated from legacy schemas, codebases, or loosely defined ontologies, where naming conventions were never designed with natural language understanding in mind.
For example, a relation named simply involves, relates, or has provides little or no semantic guidance about the kind of connection it’s actually expressing. Does the word has mean possession, classification, location, or something else entirely? Similarly, circular or self-referential definitions, like defining interaction as a type of event that involves interaction between entities, leave both humans and machines with no concrete understanding of what the concept actually means.
These kinds of modeling shortcuts may seem harmless during graph construction (they are not!), but they leave the semantics open to interpretation, which fundamentally defeats the purpose of using a knowledge graph in the first place. When such unclear terms are used as context in a RAG system, they either get ignored by the LLM or, worse, misinterpreted, leading to vague, unhelpful, or misleading answers that are difficult to trace or correct.
Detecting Quality Problems in Knowledge Graphs
In my experience, debugging a knowledge graph is most effective when approached from multiple angles, combining formal constraints, heuristic checks, and AI-assisted methods.
Logical constraints or axioms are rules that define what must always be true within the graph. For example: “An event’s end date cannot precede its start date” or “A person can only have one date of birth.” These rules are powerful for catching hard violations and can often be implemented using formal languages like OWL or SHACL. However, while they’re great at flagging structural inconsistencies, they can’t always detect semantic errors that cannot be expressed via boolean rules and conditions.
That’s where heuristics and soft rules come in. These are assumptions that may not always hold, but often indicate problems when they’re violated. For instance, “Two entities whose names have semantic similarity greater than 0.9 are probably duplicates”, or “A movie knowledge graph where most films have fewer than three actors is likely incomplete.” These rules help surface coverage issues, duplication, or skewed patterns, the kinds of problems that are harder to catch with formal logic alone.
A third approach is to use AI- and ML-based methods, which can scale quality checks and uncover issues that rules or heuristics might miss. For example, large language models can be prompted to flag vague or underspecified relation names, such as involves or relates to, embedding-based techniques can identify anomalous nodes or structural inconsistencies, and classification models can help detect type mismatches or missing connections across large, complex graphs.
At Triply, we’re currently developing a toolkit to support this multi-layered debugging process, while in my upcoming courses and posts, I’ll be diving deeper into concrete techniques for debugging and validating knowledge graphs. If you work with knowledge graphs in practice and/or want to build more trustworthy GraphRAG systems, stay tuned, subscribe, and feel free to reach out with questions, examples, or suggestions.
Thank you for reading, till next time!
Panos
News and Updates
On September 16th and 17th, 2025, I will be teaching the 7th edition of my live online course Knowledge Graphs and Large Language Models Bootcamp at the O’Reilly Learning Platform. You can see more details and register here. The course is free if you are already subscribed in the platform, and you can also take advantage of a 10-day free trial period.
On September 24th, 25th and 26th, 2025, I will be attending the PyData Amsterdam conference, giving also a masterclass with the title Grounding LLMs on Solid Knowledge: Assessing and Improving Knowledge Graph Quality in GraphRAG Applications, on the 24th. You can see more details and register here. If you are attending the conference and would like to grab a coffee and chat about data and AI please contact me.
On October 21st and 22nd, 2025, I will be teaching the 1st edition of my live online course AI Evaluations Bootcamp, at the O’Reilly Learning Platform. You can see more details and register here. The course is free if you are already subscribed in the platform, and you can also take advantage of a 10-day free trial period.
As I am writing my new book on Evaluating AI Systems, I am in the hunt for “war stories” on AI evaluation. If you have such stories, use cases, techniques, tools, or lessons you would like to share, I’d love to hear from you.
If you are interested in the field of semantic data modeling and knowledge graphs, my book Semantic Modeling for Data - Avoiding Pitfalls and Breaking Dilemmas remains available at O’Reilly, Amazon, and most known bookstores. Also, if you've already read it and have thoughts, I’d really appreciate it if you left a rating or review; it helps others discover the book and join the conversation.